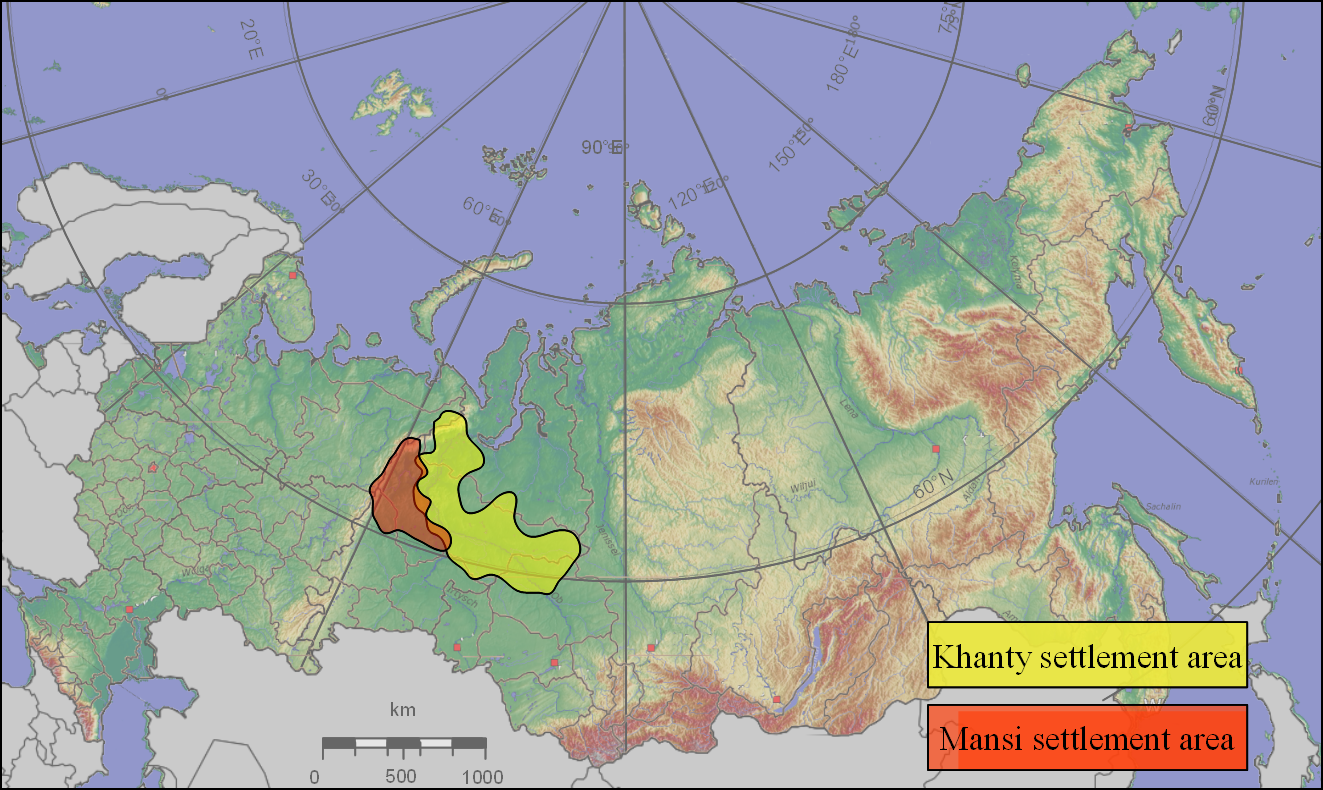
О проекте OUDBПроект «Обско-угорская база данных: анализ текстовых корпусов и словари наименее описанных обско-угорских диалектов» является преемником проекта OUL. Он был начат 1 июля 2014 г., работа в его рамках будет продолжаться до 30 июня 2017 г. Данный проект финансируется DFG (Немецкое научно-исследовательское общество) и FWF (австрийский Фонд поддержки научных исследований).Целью данного проекта является продолжение исследовательской работы, начатой проектом EUROBABEL, а также её расширение посредством систематизации, оцифровки и анализа ещё двух обско-угорских диалектов, данные по которым станут доступными в формате онлайн: западный диалект мансийского (в его пелымском, северовагильском и лозьвинском вариантах) и юганский диалект хантыйского языков. В то время как западномансийский является вымершим диалектом, и в распоряжении исследователей есть лишь текстовый материал 19 столетия, юганский диалект хантыйского языка является живым, однако находится под угрозой исчезновения; до сего дня он не был описан как самостоятельный субдиалект (восточного) сургутского диалекта хантыйского языка. Юганско-хантыйская исследовательская группа работает не только с материалами актуальных полевых исследований, но и с текстами начала 20 в. из собрания Хейкки Паасонена. В течение трёх лет работы над проектом будут созданы и включены в уже существующее виртуальное исследовательское пространство два новых модуля базы данных для двух наименее описанных диалектов. В соответствии с параметрами OUL описание и анализ будет охватывать следующие области: (a) фонологический анализ в форме IPA (за место традиционных идиосинкразических систем транскрипции), (b) определение морфологических категорий и алломорфов в данных диалектах, а также парадигмы и модели позиций для частей речи, установленных в результате анализа алломорфов. Результаты будут представлены (c) грамматическими описаниями, отсутствовавшими до настоящего времени и (d) грамматически анализированными и (e) переведёнными на все известные метаязыки (английский, частично немецкий) текстами.
Одним из результатов полевых исследований на Югане стал фотоматериал для архива полевых исследований.
С помощью систематизации фонологических и морфологических категорий исследуемых диалектов расширятся возможности их описания; это будет способствовать более точному описанию грамматических категорий обско-угорских диалектов. Будет переработана и расширена система принципов и символов (сокращений) глоссирования. Кроме того, посредством включения новых диалектов будет увеличено количество диалектологических словарей / указателей, базирующихся на текстовом корпусе, при том что во внимание будут приняты все доступные лексикографические источники и интервью с информантами. Дополнительно в рамках данного проекта будут выполнены некоторые новые задачи, которые связаны с аннотацией / анализом и их презентацией: Пользовательский интерфейс уже существующей базы данных будет снабжён дополнительными опциями для фильтрации данных лексикона и для осуществления запросов конкордации в глоссированных текстах. Как словарь, так и корпус будут расширены за счёт новых функций поиска и экспорта. Значение базы существенно возрастёт благодаря дополнительным функциям фильтрации, с помощью которых будет возможен поиск по частям речи, типам морфем, сложным формам, алломорфам, диалектическим вариантам и вариантам написания. Подобная система фильтрации является основой для учёта базирующихся на корпусе статистических данных, важнейшей предпосылкой корпусно-лингвистических работ по обско-угорским языкам. На юганском диалекте хантыйского языка, являющемся единственным рассматриваемым в проекте живым диалектом, в ходе полевого исследования должны быть записаны дополнительные тексты. С разрешения информантов данные аудиоматериалы путём фонетического тегирования в аннотационной программе ELAN должны пополнить базу данных юганско-хантыйских текстов. Таким образом могут быть более детально описаны фонетические характеристики юганского диалекта, а также установлены его морфофонологические правила. Сопоставительный анализ собственно сургутского диалекта и юганского (суб)диалекта покажет, является ли оправданной классификация последнего в качестве самостоятельного диалекта. Кроме того, многостороннюю лингвистическую информацию даст функциональный и прагматический анализ на основе принципов текстового конструирования. Принципы и количество категорий для синтаксического, семантического и информационно-структурного (IS) анализа были разработаны в проекте OUL и протестированы на нескольких текстах корпуса. Одной из насущных потребностей исследования является внедрение технического воплощения этой дифференцированной системы аннотаций в наш корпус. Эта система будет содержать (полу)автоматическую аннотацию синтаксических, семантических и прагматических ролей. Тем самым база данных сможет дать информацию по специфическим функциям морфологических категорий в текстовом корпусе.
|
|